
 Google fornisce molti servizi in tutto il mondo, e per farlo ha data-center sparsi in tutto il globo; un elemento critico di queste strutture è lo storage, ovvero i dischi da cui leggere e su cui scrivere dati. E forte di questa esperienza ha presentato alcune relazioni all’ultima conferenza FAST (File And Storage Tecnologies), nelle quali affronta due temi interessanti: i dischi per i data-center e l’affidabilità degli SSD nell’uso reale. In questo articolo mi occupo del primo tema, in uno prossimo del secondo.
Google fornisce molti servizi in tutto il mondo, e per farlo ha data-center sparsi in tutto il globo; un elemento critico di queste strutture è lo storage, ovvero i dischi da cui leggere e su cui scrivere dati. E forte di questa esperienza ha presentato alcune relazioni all’ultima conferenza FAST (File And Storage Tecnologies), nelle quali affronta due temi interessanti: i dischi per i data-center e l’affidabilità degli SSD nell’uso reale. In questo articolo mi occupo del primo tema, in uno prossimo del secondo.
Per chi vuole leggere direttamente la relazione, può trovarla qui.
In breve, Google arriva ad una conclusione: è opportuno riprogettare i dischi, sia dal punto di vista fisico (con effetti a lungo termine), sia dal punto di vista software (con potenziali effetti anche nel breve termine). Google ha tutte le capacità di realizzare in proprio le soluzioni che propone, ma vuole iniziare a discutere pubblicamente come procedere per creare dei nuovi standard, condivisi e duraturi. Ma vediamo cosa propone (e perché). Non commento tutto, ma solo le cose che trovo più interessanti.
Tutta l’analisi parte da quelle che sono le priorità in un data-center, che per Google si riducono a due:
- TCO (Total Cost of Ownership), ovvero il costo complessivo di una certa tecnologia (la somma di acquisizione, funzionamento, manutenzione e sostituzione);
- latenza, ovvero in quanto tempo sono iniziate e completate le operazioni di lettura o scrittura.
Modifiche hardware
Abbiamo subito una sorpresa (almeno per qualcuno, me compreso): per immagazzinamento a lungo termine gli SSD costano troppo. Certo, abbattono la latenza (e quindi sono usati come cache), ma in una valutazione TCO meglio la tecnologia tradizionale.
Viene fatta una considerazione forse non troppo ovvia ai non addetti ai lavori:
since data of value is never just on one disk, the bit error rate (BER) for a single disk could actually be orders of magnitude higher (i.e. lose more bits) than the current target of 1 in 10^15, assuming that we can trade off that error rate (at a fixed TCO) for something else, such as capacity or better tail latency.
siccome i dati di valore non sono mai solo su un disco, il rateo di bit errati (BER) per un singolo disco può essere in effetti di alcuni ordini di grandezza maggiore (ovvero perdere più bit) di quanto sia l’obbiettivo attuale di uno ogni 10^15, nell’ipotesi che possiamo scambiare quell’errore (a parità di costo) per qualcos’altro, come capienza o migliore latenza.
Sono presenti dei suggerimenti per superare gli attuali limiti:
- cambio del diametro dei dischi;
- aumento del numero di dischi impilati in una singola unità;
La dimensioni dei piatti (che girano fisicamente), non è una scelta frutto di una valutazione, ma semplicemente il retaggio dell’era dei floppy disk: quella era la dimensione e quella è rimasta. Dischi di dimensioni diverse avrebbero diversi vantaggi e svantaggi: dischi con diametri più piccoli potrebbero girare più velocemente e ridurre le latenze, mentre dischi con diametri maggiori aumenterebbero la capacità degli stessi. Anche l’altezza delle unità è una questione storica, e dipende dalla quantità di piatti impilati (da 3 a 5) che girano assieme e che condividono l’elettronica di controllo: Google dice di aumentare semplicemente il numero di piatti impilati.
- diminuzione della memoria cache dedicata con spostamento di tale funzione alla RAM dell’host;
- cambio della connessione da SATA/SAS a PCI-E;
- aumento del numero di testine di lettura;
- uso di mini-array: un’unità non sarebbe più composta da una pila di dischi e dalla sua elettronica, ma da una serie di pile di dischi (anche con caratteristiche diverse) e l’elettronica di controllo condivisa.
Si ipotizzano unità composte a loro volta da alcuni hard disk (si indica 4 come buon numero), magari alcuni più specializzati per la latenza e alcuni per la capacità; pur aumentando la complessità dell’unità, i vantaggi sarebbero non solo di prestazioni ma anche di costi: l’elettronica di controllo sarebbe unica dell’array, e non una per ogni hard disk.
Modifiche firmware
Google propone poi una serie di miglioramenti firmware:
- Profilazione dei dati
- Tentativi di nuova lettura gestiti dall’host
- Operazioni in backround
- Scansione in background
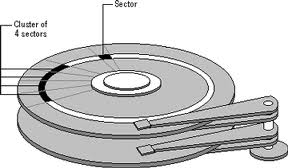
- Dimensioni più grandi del settore
- Ottimizzazione della gestione della coda.
- Dimensioni flessibili
Tutti prevedono una maggiore interazione tra il firmware del disco e la macchina che fisicamente lo usa, concentrando nel disco la gestione più semplice (ottimizzata sulle sue caratteristiche) e lasciando all’host (che ha la potenza di calcolo necessaria all’integrazione nell’infrastruttura) la gestione delle priorità di lettura o scrittura.
I mondi enterprise e consumer, anche quello di utenti esigenti come i gamer, sono sempre stati separati ma collegati: i miglioramenti tecnologici del mondo enterprise spesso erano anteprime di quelle disponibili (all’abbassamento dei prezzi) nel mondo consumer (basta pensare alla RAM DDR, il calcolo parallelo con CPU multi-core, le connessioni SATA, il bus PCI-E… e potremmo andare avanti). Queste proposte di Google sembrano poter separare ancora di più le cose, con miglioramenti tanto specifici da risultare non riversabili nel mondo consumer. Ma forse sono solo un po’ troppo pessimista.

Ho coltivato la mia passione per l’informatica fin da bambino, coi primi programmi BASIC. In età adulta mi sono avvicinato a Linux ed alla programmazione C, per poi interessarmi di reti. Infine, il mio hobby è diventato anche il mio lavoro.
Per me il modo migliore di imparare è fare, e per questo devo utilizzare le tecnologie che ritengo interessanti; a questo scopo, il mondo opensource offre gli strumenti perfetti.







Lascia un commento